Like each month, have a look at the work funded by Freexian s Debian LTS offering.
Debian project funding
Two [1, 2] projects are in the pipeline now. Tryton project is in a final phase. Gradle projects is fighting with technical difficulties.
In May, we put aside 2233 EUR to fund Debian projects.
We re looking forward to receive more projects from various Debian teams! Learn more about the rationale behind this initiative in this article.
Debian LTS contributors
In May, 14 contributors have been paid to work on Debian LTS, their reports are available:
Utkarsh Gupta did 35h (out of 19h assigned and 30h from April), thus carrying over 14h to June.
Evolution of the situation
In May we released 49 DLAs. The security tracker currently lists 71 packages with a known CVE and the dla-needed.txt file has 65 packages needing an update.
The number of paid contributors increased significantly, we are pleased to welcome our latest team members: Andreas R nnquist, Dominik George, Enrico Zini and Stefano Rivera.
It is worth pointing out that we are getting close to the end of the LTS period for Debian 9. After June 30th, no new security updates will be made available on security.debian.org. We are preparing to overtake Debian 10 Buster for the next two years and to make this process as smooth as possible.
But Freexian and its team of paid Debian contributors will continue to maintain Debian 9 going forward for the customers of the Extended LTS offer. If you have Debian 9 servers to keep secure, it s time to subscribe!
You might not have noticed, but Freexian formalized a mission statement where we explain that our purpose is to help improve Debian. For this, we want to fund work time for the Debian developers that recently joined Freexian as collaborators. The Extended LTS and the PHP LTS offers are built following a model that will help us to achieve this if we manage to have enough customers for those offers. So consider subscribing: you help your organization but you also help Debian!
Thanks to our sponsors
Sponsors that joined recently are in bold.
One month ago I started work on a new side project which is now up and running, and deserving on an introductory blog post: r2u. It was announced in two earlier tweets (first, second) which contained the two (wicked) demos below also found at the documentation site.
So what is this about? It brings full and completeCRAN installability to Ubuntu LTS, both the focal release 20.04 and the recent jammy release 22.04. It is unique in resolving all R and CRAN packages with the system package manager. So whenever you install something it is guaranteed to run as its dependencies are resolved and co-installed as needed. Equally important, no shared library will be updated or removed by the system as the possible dependency of the R package is known and declared. No other package management system for R does that as only apt on Debian or Ubuntu can and this project integrates all CRAN packages (plus 200+ BioConductor packages). It will work with any Ubuntu installation on laptop, desktop, server, cloud, container, or in WSL2 (but is limited to Intel/AMD chips, sorry Raspberry Pi or M1 laptop). It covers all of CRAN (or nearly 19k packages), all the BioConductor packages depended-upon (currently over 200), and only excludes less than a handful of CRAN packages that cannot be built.
Usage
Setup instructions approaches described concisely in the repo README.md and documentation site. It consists of just five (or fewer) simple steps, and scripts are provided too for focal (20.04) and jammy (22.04).
Demos
Check out these two demos (also at the r2u site):
Installing the full tidyverse in one command and 18 seconds
Installing brms and its depends in one command and 13 seconds (and show gitpod.io)
Integration via bspm
The r2u setup can be used directly with apt (or dpkg or any other frontend to the package management system). Once installed apt update; apt upgrade will take care of new packages. For this to work, all CRAN packages (and all BioConductor packages depended upon) are mapped to names like r-cran-rcpp and r-bioc-s4vectors: an r prefix, the repo, and the package name, all lower-cased. That works but thanks to the wonderful bspm package by I aki car we can do much better. It connects R s own install.packages() and update.packages() to apt. So we can just say (as the demos above show) install.packages("tidyverse") or install.packages("brms") and binaries are installed via apt which is fantastic and it connects R to the system package manager. The setup is really only two lines and described at the r2u site as part of the setup.
History and Motivation
Turning CRAN packages into .deb binaries is not a new idea. Albrecht Gebhardt was the first to realize this about twenty years ago (!!) and implemented it with a single Perl script. Next, Albrecht, Stefan Moeller, David Vernazobres and I built on top of this which is described in this useR! 2007 paper. A most excellent generalization and rewrite was provided by Charles Blundell in an superb Google Summer of Code contribution in 2008 which I mentored. Charles and I described it in this talk at useR! 2009. I ran that setup for a while afterwards, but it died via an internal database corruption in 2010 right when I tried to demo it at CRAN headquarters in Vienna. This peaked at, if memory serves, about 5k packages: all of CRAN at the time. Don Armstrong took it one step further in a full reimplemenation which, if I recall correctly, coverd all of CRAN and BioConductor for what may have been 8k or 9k packages. Don had a stronger system (with full RAID-5) but it also died in a crash and was never rebuilt even though he and I could have relied on Debian resources (as all these approaches focused on Debian). During that time, Michael Rutter created a variant that cleverly used an Ubuntu-only setup utilizing Launchpad. This repo is still going strong, used and relied-upon by many, and about 5k packages (per distribution) strong. At one point, a group consisting of Don, Michael, G bor Cs rdi and myself (as lead/PI) had financial support from the RConsortium ISC for a more general re-implementation , but that support was withdrawn when we did not have time to deliver.
We should also note other long-standing approaches. Detlef Steuer has been using the openSUSE Build Service to provide nearly all of CRAN for openSUSE for many years. I aki car built a similar system for Fedora described in this blog post. I aki and I also have a arXiv paper describing all this.
Details
Please see the the r2u site for all details on using r2u.
Acknowledgements
The help of everybody who has worked on this is greatly appreciated. So a huge Thank you! to Albrecht, David, Stefan, Charles, Don, Michael, Detlef, G bor, I aki and whoever I may have omitted. Similarly, thanks to everybody working on R, CRAN, Debian, or Ubuntu it all makes for a superb system. And another big Thank you! goes to my GitHub sponsors whose continued support is greatly appreciated.
Welcome to the February 2022 report from the Reproducible Builds project. In these reports, we try to round-up the important things we and others have been up to over the past month. As ever, if you are interested in contributing to the project, please visit our Contribute page on our website.
Jiawen Xiong, Yong Shi, Boyuan Chen, Filipe R. Cogo and Zhen Ming Jiang have published a new paper titled Towards Build Verifiability for Java-based Systems (PDF). The abstract of the paper contains the following:
Various efforts towards build verifiability have been made to C/C++-based systems, yet the techniques for Java-based systems are not systematic and are often specific to a particular build tool (eg. Maven). In this study, we present a systematic approach towards build verifiability on Java-based systems.
We first define the problem, and then provide insight into the challenges of making real-world software build in a reproducible manner-this is, when every build generates bit-for-bit identical results. Through the experience of the Reproducible Builds project making the Debian Linux distribution reproducible, we also describe the affinity between reproducibility and quality assurance (QA).
In openSUSE, Bernhard M. Wiedemann posted his monthly reproducible builds status report.
On our mailing list this month, Thomas Schmitt started a thread around the SOURCE_DATE_EPOCH specification related to formats that cannot help embedding potentially timezone-specific timestamp. (Full thread index.)
The Yocto Project is pleased to report that it s core metadata (OpenEmbedded-Core) is now reproducible for all recipes (100% coverage) after issues with newer languages such as Golang were resolved. This was announced in their recent Year in Review publication. It is of particular interest for security updates so that systems can have specific components updated but reducing the risk of other unintended changes and making the sections of the system changing very clear for audit.
The project is now also making heavy use of equivalence of build output to determine whether further items in builds need to be rebuilt or whether cached previously built items can be used. As mentioned in the article above, there are now public servers sharing this equivalence information. Reproducibility is key in making this possible and effective to reduce build times/costs/resource usage.
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb prepared and uploaded versions 203, 204, 205 and 206 to Debian unstable, as well as made the following changes to the code itself:
Bug fixes:
Fix a file(1)-related regression where Debian .changes files that contained non-ASCII text were not identified as such, therefore resulting in seemingly arbitrary packages not actually comparing the nested files themselves. The non-ASCII parts were typically in the Maintainer or in the changelog text. [][]
Fix a regression when comparing directories against non-directories. [][]
If we fail to scan using binwalk, return False from BinwalkFile.recognizes. []
If we fail to import binwalk, don t report that we are missing the Python rpm module! []
Testsuite improvements:
Add a test for recent file(1) issue regarding .changes files. []
Use our assert_diff utility where we can within the test_directory.py set of tests. []
Don t run our binwalk-related tests as root or fakeroot. The latest version of binwalk has some new security protection against this. []
Codebase improvements:
Drop the _PATH suffix from module-level globals that are not paths. []
Tidy some control flow in Difference._reverse_self. []
Don t print a warning to the console regarding NT_GNU_BUILD_ID changes. []
In addition, Mattia Rizzolo updated the Debian packaging to ensure that diffoscope and diffoscope-minimal packages have the same version. []
Move the contributors.sh Bash/shell script into a Python script. [][][]
Daniel Shahaf:
Try a different Markdown footnote content syntax to work around a rendering issue. [][][]
Holger Levsen:
Make a huge number of changes to the Who is involved? page, including pre-populating a large number of contributors who cannot be identified from the metadata of the website itself. [][][][][]
Improve linking to sponsors in sidebar navigation. []
drop sponsors paragraph as the navigation is clearer now. []
Upstream patches
The Reproducible Builds project attempts to fix as many currently-unreproducible packages as possible. February s patches included the following:
Testing framework
The Reproducible Builds project runs a significant testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, the following changes were made:
Daniel Golle:
Update the OpenWrt configuration to not depend on the host LLVM, adding lines to the .config seed to build LLVM for eBPF from source. []
Preserve more OpenWrt-related build artifacts. []
Holger Levsen:
Temporary use a different Git tree when building OpenWrt as our tests had been broken since September 2020. This was reverted after the patch in question was accepted by Paul Spooren into the canonical openwrt.git repository the next day.
Various improvements to debugging OpenWrt reproducibility. [][][][][]
Ignore useradd warnings when building packages. []
Update the script to powercycle armhf architecture nodes to add a hint to where nodes named virt-*. []
Update the node health check to also fix failed logrotate and man-db services. []
Mattia Rizzolo:
Update the website job after contributors.sh script was rewritten in Python. []
Make sure to set the DIFFOSCOPE environment variable when available. []
Vagrant Cascadian:
Various updates to the diffoscope timeouts. [][][]
Node maintenance was also performed by Holger Levsen [] and Vagrant Cascadian [].
Finally
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
About a month ago, I got tired of waiting for the newest member of
the Raspberry product
lineup
to be sold in Mexico, and I bought it from a Chinese reseller through
a big online shopping platform. I paid quite a bit of premium (~US$85
instead of the advertised US$15), and got it delivered ten days
later
Anyway, it s known this machine does not yet boot mainline Linux. The
vast majority of ARM systems require the bootloader to load a Device
Tree file, presenting the hardware characteristics map. And while the
RPi Zero 2 W (hey what an awful and confusing naming scheme they
chose!) is mostly similar to a RPi3B+, it is not quite the same
thing. A kernel with RPi3B+ s device tree will refuse to boot.
Anyway, I started digging, and found that some days ago Stephan
Wahren sent a patch to the linux-arm-kernel mailing
list
with a matching device tree. Read the patch! It s quite simple to read
(what is harder is to know where each declaration should go, if you
want to write your own, of course). It basically includes all basic
details for the main chip in the RPi3 family (BCM2837), pulls in also
the declarations from the BCM2836 present in the RPi2, and adds the
necessary bits for the USB OTG connection and the WiFi and Bluetooth
declarations. Registers the model name as Raspberry Pi Zero 2 W,
which you can easily see in the following photo, informs the kernel it
has 512MB RAM, and Well, really, it s an easy device tree to read,
don t be shy!
So, I booted my RPi 3B+ with a freshly downloaded Bookworm
image,
installed and unpacked linux-source-5.15, applied Stephan s patch,
and added the following for the DTB to be generated in the arm64 tree
as well:
Then, ran a simple make dtbs, and Failed, because
bcm283x-rpi-wifi-bt.dtsi is not yet in the kernel .
OK, no worries: Getting wireless to work is a later step. I commented
out the lines causing conflict (10, 33-35, 134-136), and:
root@rpi3-20220212:/usr/src/linux-source-5.15# make dtbs
DTC arch/arm64/boot/dts/broadcom/bcm2837-rpi-zero-2-w.dtb
Great!
Just copied over that generated file to /boot/firmware/, moved the SD
over to my RPiZ2W, and behold! It boots!
When I bragged about it in #debian-raspberrypi, steev suggested me
to pull in the WiFi patch, that has also been
submitted
(but not yet accepted) for kernel inclusion. I did so, uncommented the
lines I modified, and built again. It builds correctly, and again
copied the DTB over. It still does not find the WiFi; dmesg still
complains about a missing bit of firmware (failed to load
brcm/brcmfmac43430b0-sdio.raspberrypi,model-zero-2-w.bin). Steev
pointed out it can be downloaded from RPi Distro s GitHub
page,
but I called it a night and didn t pursue it any further ;-)
So I understand this post is still a far cry from saying our
images properly boot under a RPi 0 2 W ,
but we will get there
Welcome to the November 2021 report from the Reproducible Builds project.
As a quick recap, whilst anyone may inspect the source code of free software for malicious flaws, almost all software is distributed to end users as pre-compiled binaries. The motivation behind the reproducible builds effort is therefore to ensure no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised. If you are interested in contributing to our project, please visit our Contribute page on our website.
On November 6th, Vagrant Cascadian presented at this year s edition of the SeaGL conference, giving a talk titled Debugging Reproducible Builds One Day at a Time:
I ll explore how I go about identifying issues to work on, learn more about the specific issues, recreate the problem locally, isolate the potential causes, dissect the problem into identifiable parts, and adapt the packaging and/or source code to fix the issues.
In the role of a packager, updating packages is a recurring task. For some projects, a packager is involved in upstream maintenance, or well written release notes make it easy to figure out what changed between the releases. This isn t always the case, for instance with some small project maintained by one or two people somewhere on GitHub, and it can be useful to verify what exactly changed. Diffoscope can help determine the changes between package releases. []
diffoscopediffoscope is our in-depth and content-aware diff utility. Not only can it locate and diagnose reproducibility issues, it can provide human-readable diffs from many kinds of binary formats. This month, Chris Lamb made the following changes, including preparing and uploading versions 190, 191, 192, 193 and 194 to Debian:
New features:
Continue loading a .changes file even if the referenced files do not exist, but include a comment in the returned diff. []
Log the reason if we cannot load a Debian .changes file. []
Bug fixes:
Detect XML files as XML files if file(1) claims if they are XML files or if they are named .xml. (#999438)
Don t duplicate file lists at each directory level. (#989192)
Don t raise a traceback when comparing nested directories with non-directories. []
Re-enable test_android_manifest. []
Don t reject Debian .changes files if they contain non-printable characters. []
Codebase improvements:
Avoid aliasing variables if we aren t going to use them. []
Use isinstance over type. []
Drop a number of unused imports. []
Update a bunch of %-style string interpolations into f-strings or str.format. []
When pretty-printing JSON, mark the difference as being reformatted, additionally avoiding including the full path. []
Import itertools top-level module directly. []
Chris Lamb also made an update to the command-line client to trydiffoscope, a web-based version of the diffoscope in-depth and content-aware diff utility, specifically only waiting for 2 minutes for try.diffoscope.org to respond in tests. (#998360)
In addition Brandon Maier corrected an issue where parts of large diffs were missing from the output [], Zbigniew J drzejewski-Szmek fixed some logic in the assert_diff_startswith method [] and Mattia Rizzolo updated the packaging metadata to denote that we support both Python 3.9 and 3.10 [] as well as a number of warning-related changes[][]. Vagrant Cascadian also updated the diffoscope package in GNU Guix [][].
Software development
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
Elsewhere, in software development, Jonas Witschel updated strip-nondeterminism, our tool to remove specific non-deterministic results from a completed build so that it did not fail on JAR archives containing invalid members with a .jar extension []. This change was later uploaded to Debian by Chris Lamb.
reprotest is the Reproducible Build s project end-user tool to build the same source code twice in widely different environments and checking whether the binaries produced by the builds have any differences. This month, Mattia Rizzolo overhauled the Debian packaging [][][] and fixed a bug surrounding suffixes in the Debian package version [], whilst Stefano Rivera fixed an issue where the package tests were broken after the removal of diffoscope from the package s strict dependencies [].
Testing framework
The Reproducible Builds project runs a testing framework at tests.reproducible-builds.org, to check packages and other artifacts for reproducibility. This month, the following changes were made:
Holger Levsen:
Document the progress in setting up snapshot.reproducible-builds.org. []
Extend testing to include Debian bookworm too.. []
Automatically create the Jenkins view to display jobs related to building the Live images. []
Vagrant Cascadian:
Add a Debian package set group for the packages and tools maintained by the Reproducible Builds maintainers themselves. []
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Although it is possible to increase confidence in Free and Open Source Software (FOSS) by reviewing its source code, trusting code is not the same as trusting its executable counterparts. These are typically built and distributed by third-party vendors with severe security consequences if their supply chains are compromised.
In this paper, we present reproducible builds, an approach that can determine whether generated binaries correspond with their original source code. We first define the problem and then provide insight into the challenges of making real-world software build in a "reproducible" manner that is, when every build generates bit-for-bit identical results. Through the experience of the Reproducible Builds project making the Debian Linux distribution reproducible, we also describe the affinity between reproducibility and quality assurance (QA).
The full text of the paper can be found in PDF format and should appear, with an alternative layout, within a forthcoming issue of the physical IEEE Software magazine.
I released version 2.6 of ledger2beancount, a ledger to beancount converter.
Here are the changes in 2.6:
Round calculated total if needed for price==cost comparison
Add narration_tag config variable to set narration from metadata
Retain unconsummated payee/payer metadata
Ensure UTF-8 output and assume UTF-8 input
Document UTF-8 issue on Windows systems
Add option to move posting-level tags to the transaction itself
Add support for the alias sub-directive of account declarations
Add support for the payee sub-directive of account declarations
Support configuration file called .ledger2beancount.yaml
Fix uninitialised value warning in hledger mode
Print warning if account in assertion has sub-accounts
Set commodity for commodity-less balance assertion
Expand path name of beancount_header config variable
Document handling of buckets
Document pre- and post-processing examples
Add Dockerfile to create Docker image
Thanks to Alexander Baier, Daniele Nicolodi, and GitHub users bratekarate, faaafo and mefromthepast for various bug reports and other input.
Thanks to Dennis Lee for adding a Dockerfile and to Vinod Kurup for fixing a bug.
Thanks to Stefano Zacchiroli for testing.
You can get ledger2beancount from GitHub.
Team Cancel: 3028 signers from 1413 individual commit authors
Team Support: 6249 signers from 5018 individual commit authors
Git shortlog (Top 10):
rms_cancel.git (Last update: 2021-04-07 15:42:33 (UTC))
1228 Neil McGovern
251 Joan Touzet
86 Elana Hashman
71 Molly de Blanc
36 Shauna
19 Juke
18 Stefano Zacchiroli
17 Alexey Mirages
16 Devin Halladay
14 Nader Jafari
rms_support.git (Last update: 2021-04-12 09:25:53 (UTC))
1678 shenlebantongying
1564 nukeop
1550 Ivanq
826 Victor
746 Job Bautista
123 nekonee
61 Victor Gridnevsky
38 Patrick Spek
25 Borys Kabakov
17 KIM Taeyeob
(last updated 2021-04-12 09:26:15 (UTC))
Technical info:
Signers are counted from their "Signed / Individuals" sections. Commits are counted with git shortlog -s.
Team Cancel also has organizational signatures with Mozilla, Suse and X.Org being among the notable signatories.
Debian is in the process of running a GR to join (or not join) that list.
The 16 original signers of the Cancel petition are added in their count.
Neil McGovern, Juke and shenlebantongying need .mailmap support as they have committed with different names.
Further reading:
... Why do you have to be so effing difficult about a YouTube API
project that is used for a single event per year?
FOSDEM creates 600+ videos on a yearly basis. There is no way I am
going to manually upload 600+ videos through your webinterface, so we
use the API you provide, using a
script written by
Stefano Rivera. This script grabs video filenames and metadata from a
YAML file, and then uses your APIs to upload said videos with said
metadata. It works quite well. I run it from cron, and it uploads files
until the quota is exhausted, then waits until the next time the cron
job runs. It runs so well, that the first time we used it, we could
upload 50+ videos on a daily basis, and so the uploads were done as soon
as all the videos were created, which was a few months after the event.
Cool!
The second time we used the script, it did not work at all. We asked one
of our key note speakers who happened to be some hotshot at your
company, to help us out. He contacted the YouTube people, and whatever
had been broken was quickly fixed, so yay, uploads worked again.
I found out later that this is actually a normal thing if you don't use
your API quota for 90 days or more. Because it's happened to us every
bloody year.
For the 2020 event, rather than going through back channels (which
happened to be unavailable this edition), I tried to use your normal
ways of unblocking the API project. This involves creating a screencast
of a bloody command line script and describing various things that don't
apply to FOSDEM and ghaah shoot me now so meh, I created a new API
project instead, and had the uploads go through that. Doing so gives me
a limited quota that only allows about 5 or 6 videos per day, but that's
fine, it gives people subscribed to our channel the time to actually
watch all the videos while they're being uploaded, rather than being
presented with a boatload of videos that they can never watch in a day.
Also it doesn't overload subscribers, so yay.
About three months ago, I started uploading videos. Since then, every
day, the "fosdemtalks" channel on YouTube has published five or six
videos.
Given that, imagine my surprise when I found this in my mailbox this
morning...
This is an outright lie, Google.
The project has been created 90 days ago, yes, that's correct. It has
been used every day since then to upload videos.
I guess that means I'll have to deal with your broken automatic content
filters to try and get stuff unblocked...
... or I could just give up and not do this anymore. After all, all the
FOSDEM content is available on our public video
host, too.
Here is my monthly update covering what I have been doing in the free software world during December 2020 (previous month):
Reviewed and merged a contribution from Peter Law to my django-cache-toolbox library for Django-based web applications, including explicitly requiring that cached relations are primary keys (#23) and improving the example in the README (#25).
I took part in an interview with Vladimir Bejdo, an intern at the Software Freedom Conservancy, in order to talk about the Reproducible Builds project, my participation in software freedom, the importance of reproducibility in software development, and to have a brief discussion on the issues facing free software as a whole. The full interview can be found on Conservancy's webpages.
As part of my duties of being on the board of directors of the Open Source Initiative, I attended its monthly meeting and participated in various licensing and other related discussions occurring on the internet. Unfortunately, I could not attend the parallel meeting for Software in the Public Interest this month.
Reproducible Builds
One of the original promises of open source software is that distributed peer review and transparency of process results in enhanced end-user security. However, whilst anyone may inspect the source code of free and open source software for malicious flaws, almost all software today is distributed as pre-compiled binaries. This allows nefarious third-parties to compromise systems by injecting malicious code into ostensibly secure software during the various compilation and distribution processes.
The motivation behind the Reproducible Builds effort is to ensure no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised.
This month, I:
Submitted a draft academic paper to IEEE Software. The article (co-written by Stefano Zacchiroli) is aimed a fairly general audience. It first defines the overal problem and then provides insight into the challenges of actually making real-world software reproducible. It then outlines the experiences of the Reproducible Builds project in making large-scale software collections/supply-chains/ecosystems reproducible and concludes by describing the affinity between reproducibility efforts and quality assurance.
Categorised a huge number of packages and issues in the Reproducible Builds 'notes' repository.
For disorderfs (our FUSE-based filesystem that deliberately introduces non-determinism into directory system calls in order to flush out reproducibility issues), I made the following changes:
I also made a large number of changes to the main Reproducible Builds website and documentation, including applying a typo fix from Roland Clobus [...], fixed the draft detection logic (#28), added more academic articles to our list [...] and corrected a number of grammar issues [...][...].
I also made the following changes to diffoscope, our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues, including releasing version 163:
New features & bug fixes:
Normalise ret to retq in objdump output in order to support multiple versions of GNU binutils. (#976760)
Don't show any progress indicators when running zstd. (#226)
Correct the grammatical tense in the --debug log output. [...]
Codebase improvements:
Update the debian/copyright file to match the copyright notices in the source tree. (#224)
Update various years across the codebase in .py copyright headers. [...]
Rewrite the filter routine that post-processes the output from readelf(1). [...]
Remove unnecessary PEP 263 encoding header lines; unnecessary after PEP 3120. [...]
Use minimal instead of basic as a variable name to match the underlying package name. [...]
I also sponsored an upload of adminer (4.7.8-2) on behalf of Alexandre Rossi and performed two QA uploads of sendfile (2.1b.20080616-7 and 2.1b.20080616-8) to make the build the build reproducible (#776938) and to fix a number of other unrelated issues.
Debian LTS
This month I have worked 18 hours on Debian Long Term Support (LTS) and 12 hours on its sister Extended LTS project.
Frontdesk duties, responding to user/developer questions, reviewing others' packages, participating in mailing list discussions, etc.
Issued DLA 2477-1 for the Jupyter Notebook interactive notebook system, where a maliciously-crafted link could redirect the browser to a malicious/spoofed website. (CVE-2020-26215)
Issued DLA 2503-1 as it was discovered that there was an issue in node-ini, an .ini configuration file format parser/serialiser for Node.js, where an application could be exploited by a malicious input file.
You can find out more about the Debian LTS project via the following video:
Here is my monthly update covering what I have been doing in the free software world during November 2020 (previous month):
Merged a pull request from Jens Nistler for django-slack (my library which provides a convenient wrapper between projects using the Django and the Slack chat platform) to make it compatible with Celery version 5. [...]
Reproducible Builds
One of the original promises of open source software is that distributed peer review and transparency of process results in enhanced end-user security. However, whilst anyone may inspect the source code of free and open source software for malicious flaws, almost all software today is distributed as pre-compiled binaries. This allows nefarious third-parties to compromise systems by injecting malicious code into ostensibly secure software during the various compilation and distribution processes.
The motivation behind the Reproducible Builds effort is to ensure no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised.
The project is proud to be a member project of the Software Freedom Conservancy. Conservancy acts as a corporate umbrella allowing projects to operate as non-profit initiatives without managing their own corporate structure. If you like the work of the Conservancy or the Reproducible Builds project, please consider becoming an official supporter.
This month, I:
Made further progress on an academic paper in collaboration with Stefano Zacchiroli that details the theoretical and practical workings of the reproducible builds distributed consensus scheme.
Created an upstream pull request for the EmscriptenLLVM-to-WebAssembly compiler to make DOM codes reproducible (with a number of followups). [...]
Move the slightly-confusing behaviour if a single file is passed to diffoscope on the command-line to a new --load-existing-diff command. [...]
Ensure the new diffoscope-minimal package that was introduced by Mattia Rizzolo has a different short description from the primary diffoscope one. [...]
Refresh the long and short descriptions of all of the Debian packages. [...]
Bug fixes:
Don't depend on radare2 in the Debian 'autopkgtests' as it will not be in bullseye due to security considerations. (#975313)
Avoid some incorrectly-formatted error messages. This was caused by diffoscope raising an artificial CalledProcessError exception in a generic handler. [...]
Codebase improvements:
Add a comment regarding Java tests to aid diffoscope contributors who are not using Debian [...] and don't use the old-style super(...) call [...].
Debian
I performed the following uploads to the Debian Linux distribution this month:
python-django (2.2.17-1 & 3.1.3-1) New upstream releases.
splint (3.1.2+dfsg-3) Re-upload a previous QA upload of mine (3.1.2+dfsg-2) to ensure the package's transition to the testing distribution. (#974872)
I also filed a release-critical bug against the minidlna package which could not be successfully purged from the system without reporting a cannot remove '/var/log/minidlna' error. (#975372)
'Frontdesk' duties, participating in mailing list discussions, attending the monthly meeting and organising LTS and ELTS frontdesk allocations for 2021.
Issued DLA 2433-1 for the Bouncy Castle cryptography library to prevent an issue where attackers could obtain sensitive information due to observable differences in its responses to invalid input. (CVE-2020-26939)
Issued DLA 2434-1 for the GNOME display manager (gdm3) where gdm3 detecting any users may have caused gdm3 to launch the initial system setup, permitting the creation of new users with superuser capabilities. (CVE-2020-16125)
Issued DLA 2436-1 for the sddm display manager. Here, local and unprivileged users could create a connection to the X server. (CVE-2020-28049)
Issued DLA 2437-1 & ELA-308-1 as it was discovered that there was a denial of service vulnerability in the MIT Kerberos network authentication system, krb5. The lack of a limit in an ASN.1 decoder could lead to infinite recursion and allow an attacker to overrun the stack and cause the process to crash. (CVE-2020-28196)
Once a year folks interested in Netfilter technologies gather together to discuss past, ongoing and
future works. The Netfilter Workshop is an opportunity to share and discuss new ideas, the state of
the project, bring people together to work & hack and to put faces to people who otherwise are just
email names. This is an event that has been happening since at least 2001, so we are
talking about a genuine community thing here.
It was decided there would be an online format, split in 3 short meetings, once per week on
Fridays. I was unable to attend the first session on 2020-11-06 due to scheduling conflict, but I
made it to the sessions on 2020-11-13 and 2020-11-20. I would say the sessions were joined by about
8 to 10 people, depending on the day. This post is a summary with some notes on what happened in
this edition, with no special order.
Pablo did the classical review of all the changes and updates that happened in all the Netfilter
project software components since last workshop. I was unable to watch this presentation, so I have
nothing special to comment. However, I ve been following the development of the project very
closely, and there are several interesting things going on, some of them commented below.
Florian Westphal brought to the table status on some open/pending work for mptcp option matching,
systemd integration and finally interfacing from nft with cgroupv2. I was unable to participate in
the talk for the first two items, so I cannot comment a lot more. On the cgroupv2 side, several
options were evaluated to how to match them, identification methods, the hierarchical tree that
cgroups present, etc. We will have to wait a bit more to see how the final implementation looks
like.
Also, Florian presented his concerns on conntrack hash collisions. There are no real-world known
issues at the moment, but there is an old paper that suggests we should keep and eye on
this and introduce improvements to prevent future DoS attack vectors. Florian mentioned
these attacks are not practical at the moment, but who knows in a few years. He wants to explore
introducing RB trees for conntrack. It will probably be a rbtree structure of hash
tables in order to keep supporting parallel insertions. He was encouraged by others to go ahead and
play/explore with this.
Phil Sutter shared his past and future iptables development efforts. He highlighted fixed bugs and
his short/midterm TODO list. I know Phil has been busy lately fixing iptables-legacy/iptables-nft
incompatibilities. Basically addressing annoying bugs discovered by all ruleset managers out there
(kubernetes, docker, openstack neutron, etc). Lots of work has been done to improve the situation;
moreover I myself reported, or forwarded from the Debian bug tracker, several bugs. Anyway I was
unable to attend this talk, only learnt a few bits in the following sessions, so I don t have a lot
to comment here.
But when I was fully present, I was asked by Phil about the status of netfilter components in
Debian, and future plans. I shared my information. The idea for the next Debian stable release is
to don t include iptables in the installer, and include nftables instead. Since Debian
Buster, nftables is the default firewalling tool anyway. He shared the plans for the RedHat-related
ecosystem, and we were able to confirm that we are basically in sync.
Pablo commented on the latest Netfilter flowtable enhancements happening. Using the flowtable
infrastructure, one can create kernel network bypasses to speed up packet throughput. The latest
changes are aimed for bridge and VLAN enabled setups. The flowtable component will now know how
to bypass in these 2 network architectures as well as the previously supported ingress hook. This
is basically aimed for virtual machines and containers scenarios. There was some debate on use
cases and supported setups. I commented that a bunch of virtual machines connected to a classic
linux bridge and then doing NAT is basically what Openstack Neutron does, specifically in DVR
setups. Same can be found in some container-based environments. Early/simple benchmarks done by
Pablo suggest there could be huge performance improvements for those use cases.
There was some inevitable comparison of this approach to what others, like DPDK/XDP can do. A
point was raised about this being a more generic and operating system-integrated solution, which
should make it more extensible and easier to use.
Stefano Bravio commented on several open topics for nftables that he is interested on working on.
One of them, issues related to concatenations + vmap issues. He also addressed concerns with
people s expectations when migrating from ipset to nftables. There are several corner features in
ipset that aren t currently supported in nftables, and we should document them. Stefano is also
wondering about some tools to help in the migration. A translation layer like there is in place
for iptables. Eric Gaver commented there are a couple of semantics that will not be suitable for
translation, such as global sets, or sets of sets. But ipset is way simpler than iptables, so a
translation mechanism should probably be created. In any case, there was agreement that anything
that helps people migrate is more than welcome, even if it doesn t support 100% of the use cases.
Stefano is planning to write documentation in the nftables wiki on how the pipapo algorithm
works and the supported use cases. Other plans by Stefano include to work on some optimisations for
faster matches. He mentioned using architecture specific instruction to speed up sets operations,
like lookups.
Finally, he commented that some folks working with eBPF have showed interest in reusing some parts
of the nftables sets infrastructure (pipapo) because they have detected performance issues in their
own data structures in some cases. It is not clear how to best achieve it, how to better bridge the
two things together. Probably the ideal is to generalize the pipapo data structures and integrate
it into the generic bitmap library or something which can be used by anyone. Anyway, he hopes to
get some more time to focus on Netfilter stuff begining with the next year, in a couple of months.
Moving a bit away from the pure software development topics, Pablo commented on the
netfilter.org infrastructure. Right now the servers are running on gandi.net,
on virtual machines that are being basically donated to us. He pointed that the plan is to
simplify the infrastructure. For that reason, for example, FTP services has been shut down. Rsync
services have been shut down as well, so basically we no longer have a mirrors infrastructure. The
bugzilla and wikis we have need some attention, given they are old software pieces, and we need
to migrate them to be more modern. Finally, the new logo that was created was presented.
Later on, we spent a good chunk of the meeting discussing options on how to address the inevitable
iptables deprecation situation. There are some open questions, and we discussed several approaches.
From doing nothing at all, which means keeping the current status-quo, to setting a deadline date
for the deprecation like the python community did with python2. I personally like this deadline
idea, but it is perceived like a negative push by other. We all agree that the current do nothing
approach is not sustainable either. Probably the way to go is basically to be more informative. We
need to clearly communicate that choosing iptables for anything in 2020 is a bad idea. There are
additional initiatives to help on this topic, without being too aggressive. A FAQ will probably be
introduced. Eric Garver suggested we should bring nftables front and center. Given the website
still mentions iptables everywhere, we will probably refresh the web content, introduce additional
informative banners and similar things.
There was an interesting talk on the topic of nft table ownership. The idea is to attach a table,
and all the child objects, to a process. Then, we prevent any modifications to the table or the
child objects by external entities. Basically, allocating and locking a table for a certain
netlink socket. This is a nice way for ruleset managers, like firewalld, to ensure
they have full control of what s happening to their ruleset, reducing the chances for ending with
an inconsistent configuration. There is a proof-of-concept patch by Pablo to support this, and Eric
mentioned he is pretty much interested in any improvements to support this use case.
The final time block in the final session day was dedicated to talk about the next workshop.
We are all very happy we could meet. Meeting virtually is way easier (and cheaper) than in person.
Perhaps we can make it online every 3 or 6 months instead of, or in addition to, one big annual
physical event. We will see what happens next year.
That s all on my side!
I released version 2.5 of ledger2beancount, a ledger to beancount converter.
Here are the changes in 2.5:
Don't create negative cost for lot without cost
Support complex implicit conversions
Handle typed metadata with value 0 correctly
Set per-unit instead of total cost when cost is missing from lot
Support commodity-less amounts
Convert transactions with no amounts or only 0 amounts to notes
Fix parsing of transaction notes
Keep tags in transaction notes on same line as transaction header
Add beancount config options for non-standard root names automatically
Fix conversion of fixated prices to costs
Fix removal of price when price==cost but when they use different number formats
Fix removal of price when price==cost but per-unit and total notation mixed
Fix detection of tags and metadata after posting/aux date
Use D directive to set default commodity for hledger
Improve support for postings with commodity-less amounts
Allow empty comments
Preserve leading whitespace in comments in postings and transaction headers
Preserve indentation for tags and metadata
Preserve whitespace between amount and comment
Refactor code to use more data structures
Remove dependency on Config::Onion module
Thanks to input from Remco R nders, Yuri Khan, and Thierry. Thanks to Stefano Zacchiroli and Kirill Goncharov for testing my changes.
You can get ledger2beancount from GitHub
Welcome to the September 2020 report from the Reproducible Builds project. In our monthly reports, we attempt to summarise the things that we have been up to over the past month, but if you are interested in contributing to the project, please visit our main website.
This month, the Reproducible Builds project was pleased to announce a donation from Amateur Radio Digital Communications (ARDC) in support of its goals. ARDC s contribution will propel the Reproducible Builds project s efforts in ensuring the future health, security and sustainability of our increasingly digital society. Amateur Radio Digital Communications (ARDC) is a non-profit which was formed to further research and experimentation with digital communications using radio, with a goal of advancing the state of the art of amateur radio and to educate radio operators in these techniques. You can view the full announcement as well as more information about ARDC on their website.
In August s report, we announced that Jennifer Helsby (redshiftzero) launched a new reproduciblewheels.com website to address the lack of reproducibility of Python wheels . This month, Kushal Das posted a brief follow-up to provide an update on reproducible sources as well.
The Threema privacy and security-oriented messaging application announced that within the next months , their apps will become fully open source, supporting reproducible builds :
This is to say that anyone will be able to independently review Threema s security and verify that the published source code corresponds to the downloaded app.
The previous year has seen great progress in Arch Linux to get reproducible builds in the hands of the users and developers. In this talk we will explore the current tooling that allows users to reproduce packages, the rebuilder software that has been written to check packages and the current issues in this space.
During the Reproducible Builds summit in Marrakesh, GNU Guix, NixOS and Debian were able to produce a bit-for-bit identical binary when building GNU Mes, despite using three different major versions of GCC. Since the summit, additional work resulted in a bit-for-bit identical Mes binary using tcc and this month, a fuller update was posted by the individuals involved.
diffoscopediffoscope is our in-depth and content-aware diff utility that can not only locate and diagnose reproducibility issues, it provides human-readable diffs of all kinds too.
In September, Chris Lamb made the following changes to diffoscope, including preparing and uploading versions 159 and 160 to Debian:
New features:
Show ordering differences only in strings(1) output by applying the ordering check to all differences across the codebase. []
Bug fixes:
Mark some PGP tests that they require pgpdump, and check that the associated binary is actually installed before attempting to run it. (#969753)
Don t raise exceptions when cleaning up after guestfs cleanup failure. []
Ensure we check FALLBACK_FILE_EXTENSION_SUFFIX, otherwise we run pgpdump against all files that are recognised by file(1) as data. []
Codebase improvements:
Add some documentation for the EXTERNAL_TOOLS dictionary. []
Abstract out a variable we use a couple of times. []
Improve the documentation on how to signup to Salsa. []
Add some more links to academic papers. []
Also include the general news in our RSS feed [] and drop including weekly reports from the RSS feed (they are never shown now that we have over 10 items) [].
Update ordering and location of various news and links to tarballs, etc. [][][]
In addition, Holger Levsen re-added the documentation link to the top-level navigation [] and documented that the jekyll-polyglot package is required []. Lastly, diffoscope.org and reproducible-builds.org were transferred to Software Freedom Conservancy. Many thanks to Brett Smith from Conservancy, J r my Bobbio (lunar) and Holger Levsen for their help with transferring and to Mattia Rizzolo for initiating this.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of these patches, including:
Testing framework
The Reproducible Builds project operates a Jenkins-based testing framework to power tests.reproducible-builds.org. This month, Holger Levsen made the following changes:
Highlight important bad conditions in colour. [][]
Add support for detecting more problems, including Jenkins shutdown issues [], failure to upgrade Arch Linux packages [], kernels with wrong permissions [], etc.
Misc:
Delete old schroot sessions after 2 days, not 3. []
In addition, stefan0xC fixed a query for unknown results in the handling of Arch Linux packages [] and Mattia Rizzolo updated the template that notifies maintainers by email of their newly-unreproducible packages to ensure that it did not get caught in junk/spam folders []. Finally, build node maintenance was performed by Holger Levsen [][][][], Mattia Rizzolo [][] and Vagrant Cascadian [][][].
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
Dealing with the void during MiniDebConf Online #1
Between 28 and 31 May this year, we set out to create our first ever online MiniDebConf for Debian. Many people have been meaning to do something similar for a long time, but it just didn t work out yet. With many of us being in lock down due to COVID-19, and with the strong possibility looming that DebConf20 might have had to become an online event, we rushed towards organising the first ever Online MiniDebConf and put together some form of usable video stack for it.
I could go into all kinds of details on the above, but this post is about a bug that lead to a pretty nifty feature for DebConf20. The tool that we use to capture Jitsi calls is called Jibri (Jitsi Broadcasting Infrustructure). It had a bug (well, bug for us, but it s an upstream feature) where Jibri would hang up after 30s of complete silence, because it would assume that the call has ended and that the worker can be freed up again. This would result in the stream being ended at the end of every talk, so before the next talk, someone would have to remember to press play again in their media player or on the video player on the stream page. Hrmph.
Easy solution on the morning that the conference starts? I was testing a Debian Live image the night before in a KVM and thought that I might as well just start a Jitsi call from there and keep a steady stream of silence so that Jibri doesn t hang up.
It worked! But the black screen and silence on stream was a bit eery. Because this event was so experimental in nature, and because we were on such an incredibly tight timeline, we opted not to seek sponsors for this event, so there was no sponsors loop that we d usually stream during a DebConf event. Then I thought Ah! I could just show the schedule! .
The stream looked bright and colourful (and was even useful!) and Jitsi/Jibri didn t die. I thought my work was done. As usual, little did I know how untrue that was.
The silence was slightly disturbing after the talks, and people asked for some music. Playing music on my VM and capturing the desktop audio in to Jitsi was just a few pulseaudio settings away, so I spent two minutes finding some freely licensed tracks that sounded ok enough to just start playing on the stream. I came across mini-albums by Captive Portal and Cinema Noir, During the course of the MiniDebConf Online I even started enjoying those. Someone also pointed out that it would be really nice to have a UTC clock on the stream. I couldn t find a nice clock in a hurry so I just added a tmux clock in the meantime while we deal with the real-time torrent of issues that usually happens when organising events like this.
Speaking of issues, during our very first talk of the last day, our speaker had a power cut during the talk and abruptly dropped off. Oops! So, since I had a screenshare open from the VM to the stream, I thought I d just pop in a quick message in a text editor to let people know that we re aware of it and trying to figure out what s going on.
In the end, MiniDebConf Online worked out all right. Besides the power cut for our one speaker, and another who had a laptop that was way too under-powered to deal with video, everything worked out very well. Even the issues we had weren t show-stoppers and we managed to work around them.
DebConf20 Moves Online
For DebConf, we usually show a sponsors loop in between sessions. It s great that we give our sponsors visibility here, but in reality people see the sponsors loop and think Talk over! and then they look away. It s also completely silent and doesn t provide any additional useful information. I was wondering how I could take our lessons from MDCO#1 and integrate our new tricks with the sponsors loop. That is, add the schedule, time, some space to type announcements on the screen and also add some loopable music to it.
I used OBS before in making my videos, and like the flexibility it provides when working with scenes and sources. A scene is what you would think of as a screen or a document with its own collection of sources or elements. For example, a scene might contain sources such as a logo, clock, video, image, etc. A scene can also contain another scene. This is useful if you want to contain a banner or play some background music that is shared between scenes.
The above screenshots illustrate some basics of scenes and sources. First with just the DC20 banner, and then that used embedded in another scene.
For MDCO#1, I copied and pasted the schedule into a LibreOffice Impress slide that was displayed on the stream. Having to do this for all 7 days of DebConf, plus dealing with scheduling changes would be daunting. So, I started to look in to generating some schedule slides programmatically. Stefano then pointed me to the Happening Now page on the DebConf website, where the current schedule block is displayed. So all I would need to do in OBS was to display a web page. Nice!
Unfortunately the OBS in Debian doesn t have the ability to display web pages out of the box (we need to figure out CEF in Debian), but fortunately someone provides a pre-compiled version of the plugin called Linux Browser that works just fine. This allowed me to easily add the schedule page in its own scene.
Being able to display a web page solved another problem. I wasn t fond of having to type / manage the announcements in OBS. It would either be a bit prone to user error, and if you want to edit the text while the loop is running, you d have to disrupt the loop, go to the foreground scene, and edit the text before resuming the loop. That s a bit icky. Then I thought that we could probably just get that from a web page instead. We could host some nice html snippet in a repository in salsa, and then anyone could easily commit an MR to update the announcement.
But then I went a step further, use an etherpad! Then anyone in the orga team can quickly update the announcement and it would be instantly changed on the stream. Nice! So that small section of announcement text on the screen is actually a whole web browser with an added OBS filter to crop away all the pieces we don t want. Overkill? Sure, but it gave us a decent enough solution that worked in time for the start of DebConf. Also, being able to type directly on to the loop screen works out great especially in an emergency. Oh, and uhm the clock is also a website rendered in its own web browser :-P
So, I had the ability to make scenes, add elements and add all the minimal elements I wanted in there. Great! But now I had to figure out how to switch scenes automatically. It s probably worth mentioning that I only found some time to really dig into this right before DebConf started, so with all of this I was scrambling to find things that would work without too many bugs while also still being practical.
Now I needed the ability to switch between the scenes automatically / programmatically. I had never done this in OBS before. I know it has some API because there are Android apps that you can use to control OBS with from your phone. I discovered that it had an automatic scene switcher, but it s very basic. It can only switch based on active window, which can be useful in some cases, but since we won t have any windows open other than OBS, this tool was basically pointless.
After some quick searches, I found a plugin called Advanced Scene Switcher. This plugin can do a lot more, but has some weird UI choices, and is really meant for gamers and other types of professional streamers to help them automate their work flow and doesn t seem at all meant to be used for a continuous loop, but, it worked, and I could make it do something that will work for us during the DebConf.
I had a chicken and egg problem because I had to figure out a programming flow, but didn t really have any content to work with, or an idea of all the content that we would eventually have. I ve been toying with the idea in my mind and had some idea that we could add fun facts, postcards (an image with some text), time now in different timezones, Debian news (maybe procured by the press team), cards that contain the longer announcements that was sent to debconf-announce, perhaps a shout out or two and some photos from previous DebConfs like the group photos. I knew that I wouldn t be able to build anything substantial by the time DebConf starts, but adding content to OBS in between talks is relatively easy, so we could keep on building on it during DebConf.
Nattie provided the first shout out, and I made 2 video loops with the DC18/19 pictures and also two Did you know cards. So the flow I ended up with was: Sponsors -> Happening Now -> Random video (which would be any of those clips) -> Back to sponsors. This ended up working pretty well for quite a while. With the first batch of videos the sponsor loop would come up on average about every 2 minutes, but as much shorter clips like shout outs started to come in faster and faster, it made sense to play a few 2-3 shout-outs before going back to sponsors.
So here is a very brief guide on how I set up the sequencing in Advanced Scene Switcher.
If no condition was met, a video would play from the Random tab.
Then in the Random tab, I added the scenes that were part of the random mix. Annoyingly, you have to specify how long it should play for. If you don t, the no condition thingy is triggered and another video is selected. The time is also the length of the video minus one second, because
You can t just say that a random video should return back to a certain scene, you have to specify that in the sequence tab for each video. Why after 1 second? Because, at least in my early tests, and I didn t circle back to this, it seems like 0s can randomly either mean instantly, or never. Yes, this ended up being a bit confusing and tedious, and considering the late hours I worked on this, I m surprised that I didn t manage to screw it up completely at any point.
I also suspected that threads would eventually happen. That is, when people create video replies to other videos. We had 3 threads in total. There was a backups thread, beverage thread and an impersonation thread. The arrow in the screenshot above points to the backups thread. I know it doesn t look that complicated, but it was initially somewhat confusing to set up and make sense out of it.
For the next event, the Advanced Scene Switcher might just get some more taming, or even be replaced entirely. There are ways to drive OBS by API, and even the Advanced Scene Switcher tool can be driven externally to some degree, but I think we definitely want to replace it by the next full DebConf. We had the problem that when a talk ended, we would return to the loop in the middle of a clip, which felt very unnatural and sometimes even confusing. So Stefano helped me with a helper script that could read the socket from Vocto, which I used to write either Loop or Standby to a file, and then the scene switcher would watch that file and keep the sponsors loop ready for start while the talks play. Why not just switch to sponsors when the talk ends? Well, the little bit of delay in switching would mean that you would see a tiny bit of loop every time before switching to sponsors. This is also why we didn t have any loop for the ad-hoc track (that would have probably needed another OBS instance, we ll look more into solutions for this for the future).
Then for all the clips. There were over 50 of them. All of them edited by hand in kdenlive. I removed any hard clicks, tried to improve audibility, remove some sections at the beginning and the end that seemed extra and added some music that would reduce in volume when someone speaks. In the beginning, I had lots of fun with choosing music for the clips. Towards the end, I had to rush them through and just chose the same tune whether it made sense or not. For comparison of what a difference the music can make, compare the original and adapted version for Valhalla s clip above, or this original and adapted video from urbec. This part was a lot more fun than dealing with the video sequencer, but I also want to automate it a bit. When I can fully drive OBS from Python I ll likely instead want to show those cards and control music volume from Python (what could possibly go wrong ).
The loopy name happened when I requested an @debconf.org alias for this. I was initially just thinking about loop@debconf.org but since I wanted to make it clear that the purpose of this loop is also to have some fun, I opted for loopy instead:
I was really surprised by how people took to loopy. I hoped it would be good and that it would have somewhat positive feedback, but the positive feedback was just immense. The idea was that people typically saw it in between talks. But a few people told me they kept it playing after the last talk of the day to watch it in the background. Some asked for the music because they want to keep listening to it while working (and even for jogging!?). Some people also asked for recordings of the loop because they want to keep it for after DebConf. The shoutouts idea proved to be very popular. Overall, I m very glad that people enjoyed it and I think it s safe to say that loopy will be back for the next event.
Also throughout this experiment Loopy Loop turned into yet another DebConf mascot. We gain one about every DebConf, some by accident and some on purpose. This one was not quite on purpose. I meant to make an image for it for salsa, and started with an infinite loop symbol. That s a loop, but by just adding two more solid circles to it, it looks like googly eyes, now it s a proper loopy loop!
I like the progress we ve made on this, but there s still a long way to go, and the ideas keep heaping up. The next event is quite soon (MDCO#2 at the end of November, and it seems that 3 other MiniDebConf events may also be planned), but over the next few events there will likely be significantly better graphics/artwork, better sequencing, better flow and more layout options. I hope to gain some additional members in the team to deal with incoming requests during DebConf. It was quite hectic this time! The new OBS also has a scripting host that supports Python, so I should be able to do some nice things even within OBS without having to drive it externally (like, display a clock without starting a web browser).
The Loopy Loop Music
The two mini albums that mostly played during the first few days were just a copy and paste from the MDCO#1 music, which was:
I have much more things to say about DebConf20, but I ll keep that for another post, and hopefully we can get all the other video stuff in a post from the video team, because I think there s been some real good work done for this DebConf. Also thanks to Infomaniak who was not only a platinum sponsor for this DebConf, but they also provided us with plenty of computing power to run all the video stuff on. Thanks again!
I released version 2.4 of ledger2beancount, a ledger to beancount converter.
There are two notable changes in this release:
I fixed two regressions introduced in the last release. Sorry about the breakage!
I improved support for hledger. I believe all syntax differences in hledger are supported now.
Here are the changes in 2.4:
Fix regressions introduced in version 2.3
Handle price directives with comments
Don't assume implicit conversion when price is on second posting
Improve support for hledger
Fix parsing of hledger tags
Support commas as decimal markers
Support digit group marks through commodity and D directives
Support end aliases directive
Support regex aliases
Recognise total balance assertions
Recognise sub-account balance assertions
Add support for define directive
Convert all uppercase metadata tags to all lowercase
Improve handling of ledger lots without cost
Allow transactions without postings
Fix parsing issue in commodity declarations
Support commodities that contain quotation marks
Add --version option to show version
Document problem of mixing apply and include
Thanks to Kirill Goncharov for pointing out one regressions, to Taylor R Campbell for for a patch, to Stefano Zacchiroli for some input, and finally to Simon Michael for input on hledger!
You can get ledger2beancount from GitHub
DebConf20 starts in about 5 weeks, and as always, the DebConf
Videoteam is working hard to make sure it'll be a success. As such, we held a
sprint from July 9th to 13th to work on our new infrastructure.
A remote sprint certainly ain't as fun as an in-person one, but we nonetheless
managed to enjoy ourselves. Many thanks to those who participated, namely:
Carl Karsten (CarlFK)
Ivo De Decker (ivodd)
Kyle Robbertze (paddatrapper)
Louis-Philippe V ronneau (pollo)
Nattie Mayer-Hutchings (nattie)
Nicolas Dandrimont (olasd)
Stefano Rivera (tumbleweed)
Wouter Verhelst (wouter)
We also wish to extend our thanks to Thomas Goirand and Infomaniak for
providing us with virtual machines to experiment on and host the video
infrastructure for DebConf20.
Advice for presenters
For DebConf20, we strongly encourage presenters to record their talks in
advance and send us the resulting video. We understand this is more work,
but we think it'll make for a more agreeable conference for everyone. Video
conferencing is still pretty wonky and there is nothing worse than a talk
ruined by a flaky internet connection or hardware failures.
As such, if you are giving a talk at DebConf this year, we are asking you to
read and follow our guide on how to record your presentation.
Fear not: we are not getting rid of the Q&A period at the end of talks.
Attendees will ask their questions either on IRC or on a collaborative pad
and the Talkmeister will relay them to the speaker once the pre-recorded
video has finished playing.
New infrastructure, who dis?
Organising a virtual DebConf implies migrating from our battle-tested
on-premise workflow to a completely new remote one.
One of the major changes this means for us is the addition of Jitsi Meet to our
infrastructure. We normally have 3 different video sources in a room: two
cameras and a slides grabber. With the new online workflow, directors will be
able to play pre-recorded videos as a source, will get a feed from a Jitsi room
and will see the audience questions as a third source.
This might seem simple at first, but is in fact a very major change to our
workflow and required a lot of work to implement.
== On-premise == == Online ==
Camera 1 Jitsi
v ---> Frontend v ---> Frontend
Slides -> Voctomix -> Backend -+--> Frontend Questions -> Voctomix -> Backend -+--> Frontend
^ ---> Frontend ^ ---> Frontend
Camera 2 Pre-recorded video
In our tests, playing back pre-recorded videos to voctomix worked well, but was
sometimes unreliable due to inconsistent encoding settings. Presenters will
thus upload their pre-recorded talks to SReview so we can make sure there
aren't any obvious errors. Videos will then be re-encoded to ensure a
consistent encoding and to normalise audio levels.
This process will also let us stitch the Q&As at the end of the pre-recorded
videos more easily prior to publication.
Reducing the stream latency
One of the pitfalls of the streaming infrastructure we have been using since
2016 is high video latency. In a worst case scenario, remote attendees could
get up to 45 seconds of latency, making participation in events like BoFs
arduous.
In preparation for DebConf20, we added a new way to stream our talks: RTMP.
Attendees will thus have the option of using either an HLS stream with higher
latency or an RTMP stream with lower latency.
Here is a comparative table that can help you decide between the two protocols:
HLS
RTMP
Pros
Can be watched from a browser
Auto-selects a stream encoding
Single URL to remember
Lower latency (~5s)
Cons
Higher latency (up to 45s)
Requires a dedicated video player (VLC, mpv)
Specific URLs for each encoding setting
Live mixing from home with VoctoWeb
Since DebConf16, we have been using voctomix, a live video mixer developed
by the CCC VOC. voctomix is conveniently divided in two: voctocore is the
backend server while voctogui is a GTK+ UI frontend directors can use to
live-mix.
Although voctogui can connect to a remote server, it was primarily designed to
run either on the same machine as voctocore or on the same LAN. Trying to use
voctogui from a machine at home to connect to a voctocore running in a
datacenter proved unreliable, especially for high-latency and low bandwidth
connections.
Inspired by the setup FOSDEM uses, we instead decided to go with a web frontend
for voctocore. We initially used FOSDEM's code as a proof of
concept, but quickly reimplemented it in Python, a language we are more
familiar with as a team.
Compared to the FOSDEM PHP implementation, voctoweb implements A / B source
selection (akin to voctogui) as well as audio control, two very useful
features. In the following screen captures, you can see the old PHP UI on the
left and the new shiny Python one on the right.
Voctoweb is still under development and is likely to change quite a bit
until DebConf20. Still, the current version seems to works well enough to be
used in production if you ever need to.
Python GeoIP redirector
We run multiple geographically-distributed streaming frontend servers to
minimize the load on our streaming backend and to reduce overall latency.
Although users can connect to the frontends directly, we typically point them
to live.debconf.org and redirect connections to the nearest server.
Sadly, 6 months ago MaxMind decided to change the licence on their
GeoLite2 database and left us scrambling. To fix this annoying issue, Stefano
Rivera wrote a Python program that uses the new database and reworked our
ansible frontend server role. Since the new database cannot be
redistributed freely, you'll have to get a (free) license key from MaxMind if
you to use this role.
Ansible & CI improvements
Infrastructure as code is a living process and needs constant care to fix bugs,
follow changes in DSL and to implement new features. All that to say a large
part of the sprint was spent making our ansible roles and continuous
integration setup more reliable, less buggy and more featureful.
All in all, we merged 26 separate ansible-related merge request during the
sprint! As always, if you are good with ansible and wish to help, we accept
merge requests on our ansible repository :)
As nationwide protests over the deaths of George Floyd and Breonna Taylor are met with police brutality, John Oliver discusses how the histories of policing ...
La morte di Stefano Cucchi avvenne a Roma il 22 ottobre 2009 mentre il giovane era sottoposto a custodia cautelare. Le cause della morte e le responsabilit sono oggetto di procedimenti giudiziari che hanno coinvolto da un lato i medici dell'ospedale Pertini,[1][2][3][4] dall'altro continuano a coinvolgere, a vario titolo, pi militari dell Arma dei Carabinieri[5][6]. Il caso ha attirato l'attenzione dell'opinione pubblica a seguito della pubblicazione delle foto dell'autopsia, poi riprese da agenzie di stampa, giornali e telegiornali italiani[7]. La vicenda ha ispirato, altres , documentari e lungometraggi cinematografici.[8][9][10]
La morte di Giuseppe Uva avvenne il 14 giugno 2008 dopo che, nella notte tra il 13 e il 14 giugno, era stato fermato ubriaco da due carabinieri che lo portarono in caserma, dalla quale venne poi trasferito, per un trattamento sanitario obbligatorio, nell'ospedale di Varese, dove mor la mattina successiva per arresto cardiaco. Secondo la tesi dell'accusa, la morte fu causata dalla costrizione fisica subita durante l'arresto e dalle successive violenze e torture che ha subito in caserma. Il processo contro i due carabinieri che eseguirono l'arresto e contro altri sei agenti di polizia ha assolto gli imputati dalle accuse di omicidio preterintenzionale e sequestro di persona[1][2][3][4]. Alla vicenda dedicato il documentario Viva la sposa di Ascanio Celestini[1][5].
Il caso Aldrovandi la vicenda giudiziaria causata dall'uccisione di Federico Aldrovandi, uno studente ferrarese, avvenuta il 25 settembre 2005 a seguito di un controllo di polizia.[1][2][3] I procedimenti giudiziari hanno condannato, il 6 luglio 2009, quattro poliziotti a 3 anni e 6 mesi di reclusione, per "eccesso colposo nell'uso legittimo delle armi";[1][4] il 21 giugno 2012 la Corte di cassazione ha confermato la condanna.[1] All'inchiesta per stabilire la cause della morte ne sono seguite altre per presunti depistaggi e per le querele fra le parti interessate.[1] Il caso stato oggetto di grande attenzione mediatica e ha ispirato un documentario, stato morto un ragazzo.[1][5]
I released version 2.3 of ledger2beancount,
a ledger to beancount converter.
There are three notable changes with this release:
Performance has significantly improved. One large, real-world test case has gone from around 160 seconds to 33 seconds. A smaller test case has gone from 11 seconds to ~3.5 seconds.
Improve parsing of postings for accuracy and speed
Improve support for inline math
Handle lots without cost
Fix parsing of lot notes followed by a virtual price
Add support for lot value expressions
Make parsing of numbers more strict
Fix behaviour of dates without year
Accept default ledger date formats without configuration
Fix implicit conversions with negative prices
Convert implicit conversions in a more idiomatic way
Avoid introducing trailing whitespace with hledger input
Fix loading of config file
Skip ledger directive import
Convert documentation to mkdocs
Thanks to Colin Dean for some feedback. Thanks to Stefano Zacchiroli for prompting me into investigating performance issues (and thanks to the developers of the Devel::NYTProf profiler).
You can get ledger2beancount from GitHub
Something I ve found myself doing as the pandemic rolls on is picking
out and (re-)reading through sections of the GNU Emacs
manual and the
GNU Emacs Lisp reference
manual. This
has got me (too) interested in some of the recent history of Emacs
development, and I did some digging into archives of emacs-devel from
2008 (15M
mbox) regarding the change to turn Transient Mark mode on by default
and set mark-even-if-inactive to true by default in Emacs 23.1.
It s not always clear which objections to turning on Transient Mark
mode by default take into account the mark-even-if-inactive change.
I think that turning on Transient Mark mode along with
mark-even-if-inactive is a good default. The question that remains
is whether the disadvantages of Transient Mark mode are significant
enough that experienced Emacs users should consider altering Emacs
default behaviour to mitigate them. Here s one popular blog arguing
for some
mitigations.
How might Transient Mark mode be disadvantageous?
The suggestion is that it makes using the mark for navigation rather
than for acting on regions less convenient:
setting a mark just so you can jump back to it (i) is a distinct
operation you have to think of separately; and (ii) requires two
keypresses, C-SPC C-SPC, rather than just one keypress
using exchange-point-and-mark activates the region, so to use it
for navigation you need to use either C-u C-x C-x or C-x C-x
C-g, neither of which are convenient to type, or else it will be
difficult to set regions at the place you ve just jumped to because
you ll already have one active.
There are two other disadvantages that people bring up which I am
disregarding. The first is that it makes it harder for new users to
learn useful ways in which to use the mark when it s deactivated.
This happened to me, but it can be mitigated without making any
behavioural changes to Emacs. The second is that the visual
highlighting of the region can be distracting. So far as I can tell,
this is only a problem with exchange-point-and-mark, and it s
subsumed by the problem of that command actually activating the
region. The rest of the time Emacs automatic deactivation of the
region seems sufficient.
How might disabling Transient Mark mode be disadvantageous?
When Transient Mark mode is on, many commands will do something
usefully different when the mark is active. The number of commands in
Emacs which work this way is only going to increase now that Transient
Mark mode is the default.
If you disable Transient Mark mode, then to use those features you
need to temporarily activate Transient Mark mode. This can be fiddly
and/or require a lot of keypresses, depending on exactly where you
want to put the region.
Without being able to see the region, it might be harder to know where
it is. Indeed, this is one of the main reasons for wanting Transient
Mark mode to be the default, to avoid confusing new users. I don t
think this is likely to affect experienced Emacs users often, however,
and on occasions when more precision is really needed, C-u C-x C-x
will make the region visible. So I m not counting this as a
disadvantage.
How might we mitigate these two sets of disadvantages?
Here are the two middle grounds I m considering.
Mitigation #1: Transient Mark mode, but hack C-x C-x behaviour
(defunspw/exchange-point-and-mark (arg)"Exchange point and mark, but reactivate mark a bit less often.Specifically, invert the meaning of ARG in the case whereTransient Mark mode is on but the region is inactive."(interactive"P")(exchange-point-and-mark(if(and transient-mark-mode (not mark-active))(not arg)
arg)))(global-set-key[remap exchange-point-and-mark] &aposspw/exchange-point-and-mark)
We avoid turning Transient Mark mode off, but mitigate the second of
the two disadvantages given above.
I can t figure out why it was thought to be a good idea to make C-x
C-x reactivate the mark and require C-u C-x C-x to use the action
of exchanging point and mark as a means of navigation. There needs to
a binding to reactivate the mark, but in roughly ten years of having
Transient Mark mode turned on, I ve found that the need to reactivate
the mark doesn t come up often, so the shorter and longer bindings
seem the wrong way around. Not sure what I m missing here.
Mitigation #2: disable Transient Mark mode, but enable it temporarily more often
(setq transient-mark-mode nil)(defunspw/remap-mark-command (command&optional map)"Remap a mark-* command to temporarily activate Transient Mark mode."(let* ((cmd(symbol-name command))(fun(intern(concat"spw/" cmd)))(doc(concat"Call "
cmd
"&apos and temporarily activate Transient Mark mode.")))(fset fun (lambda(),doc
(interactive)(call-interactively#&apos,command)(activate-mark)))(if map
(define-key map (vector&aposremap command) fun)(global-set-key(vector&aposremap command) fun))))(dolist(command&apos(mark-word
mark-sexp
mark-paragraph
mark-defun
mark-page
mark-whole-buffer))(spw/remap-mark-command command))(with-eval-after-load&aposorg
(spw/remap-mark-command &aposorg-mark-element org-mode-map)(spw/remap-mark-command &aposorg-mark-subtree org-mode-map));; optional(global-set-key"\M-="(lambda() (interactive) (activate-mark)));; resettle the previous occupant(global-set-key"\C-cw"&aposcount-words-region)
Here we remove both of the disadvantages of Transient Mark mode given
above, and mitigate the main disadvantage of not activating Transient
Mark mode by making it more convenient to activate it temporarily.
For example, this enables using C-M-SPC C-M-SPC M-( to wrap the
following two function arguments in parentheses. And you can hit
M-h a few times to mark some blocks of text or code, then operate on
them with commands like M-% and C-/ which behave differently when
the region is active.1
Comparing these mitigations
Both of these mitigations handle the second of the two disadvantages
of Transient Mark mode given above. What remains, then, is
under the effects of mitigation #1, how much of a barrier to using
marks for navigational purposes is it to have to press C-SPC
C-SPC instead of having a single binding, C-SPC, for all manual
mark setting2
under the effects of mitigation #2, how much of a barrier to taking
advantage of commands which act differently when the region is
active is it to have to temporarily enable Transient Mark mode with
C-SPC C-SPC, M-= or one of the mark-* commands?
These are unknowns.3 So I m going to have to experiment, I think,
to determine which mitigation to use, if either. In particular, I
don t know whether it s really significant that setting a mark for
navigational purposes and for region marking purposes are distinct
operations under mitigation #1.
My plan is to start with mitigation #2 because that has the additional
advantage of allowing me to confirm or disconfirm my belief that not
being able to see where the region is will only rarely get in my way.
The idea of making the mark-* commands activate the mark comes
from an emacs-devel post by Stefan Monnier in the archives linked
above.
One remaining possibility I m not considering is mitigation #1
plus binding something else to do the same as C-SPC C-SPC. I
don t believe there are any easily rebindable keys which are
easier to type than typing C-SPC twice. And this does not deal
with the two distinct mark-setting operations problem.
Another way to look at this is the question of which of setting
a mark for navigational purposes and activating a mark should get
C-SPC and which should get C-SPC C-SPC.


 One month ago I started work on a new side project which is now up and running, and deserving on an introductory blog post:
One month ago I started work on a new side project which is now up and running, and deserving on an introductory blog post: 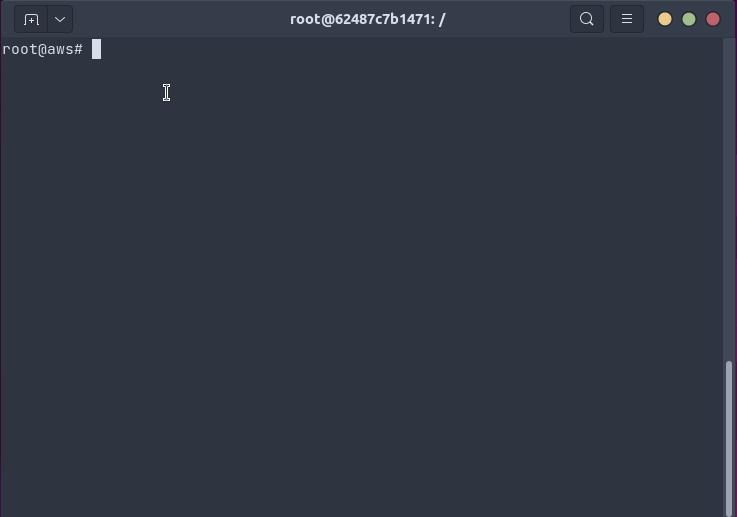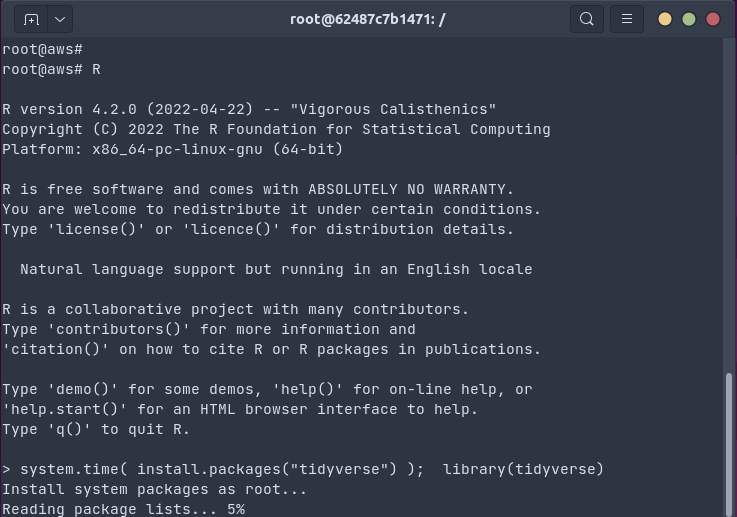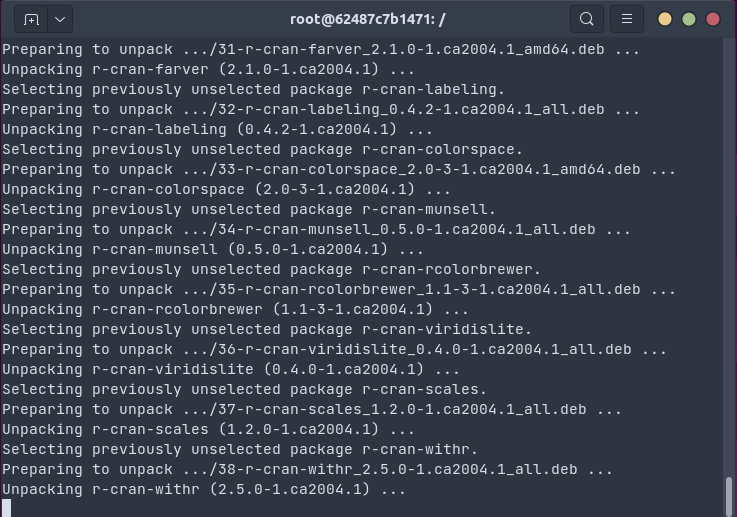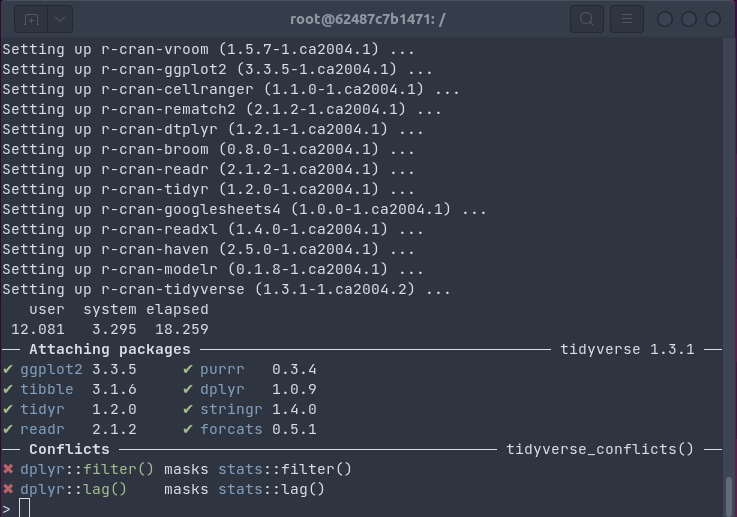








 About a month ago, I got tired of waiting for the
About a month ago, I got tired of waiting for the 








 I didn't blog about it at the time, but a paper I co-authored with
I didn't blog about it at the time, but a paper I co-authored with  I released version 2.6 of
I released version 2.6 of  So, 2021 isn't bad enough yet, but don't despair, people are working to fix that:
So, 2021 isn't bad enough yet, but don't despair, people are working to fix that:
 ... Why do you have to be so effing difficult about a YouTube API
project that is used for
... Why do you have to be so effing difficult about a YouTube API
project that is used for 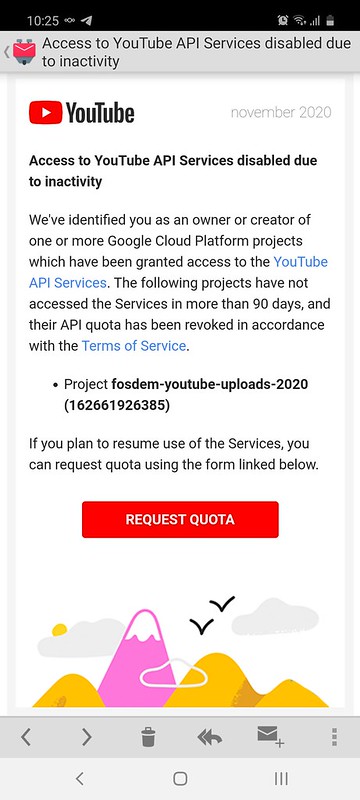
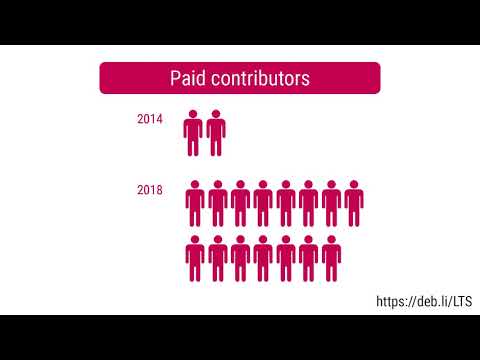
 Stefano Bravio commented on several open topics for nftables that he is interested on working on.
One of them, issues related to concatenations + vmap issues. He also addressed concerns with
people s expectations when migrating from ipset to nftables. There are several corner features in
ipset that aren t currently supported in nftables, and we should document them. Stefano is also
wondering about some tools to help in the migration. A translation layer like there is in place
for iptables. Eric Gaver commented there are a couple of semantics that will not be suitable for
translation, such as global sets, or sets of sets. But ipset is way simpler than iptables, so a
translation mechanism should probably be created. In any case, there was agreement that anything
that helps people migrate is more than welcome, even if it doesn t support 100% of the use cases.
Stefano is planning to write documentation in the
Stefano Bravio commented on several open topics for nftables that he is interested on working on.
One of them, issues related to concatenations + vmap issues. He also addressed concerns with
people s expectations when migrating from ipset to nftables. There are several corner features in
ipset that aren t currently supported in nftables, and we should document them. Stefano is also
wondering about some tools to help in the migration. A translation layer like there is in place
for iptables. Eric Gaver commented there are a couple of semantics that will not be suitable for
translation, such as global sets, or sets of sets. But ipset is way simpler than iptables, so a
translation mechanism should probably be created. In any case, there was agreement that anything
that helps people migrate is more than welcome, even if it doesn t support 100% of the use cases.
Stefano is planning to write documentation in the 










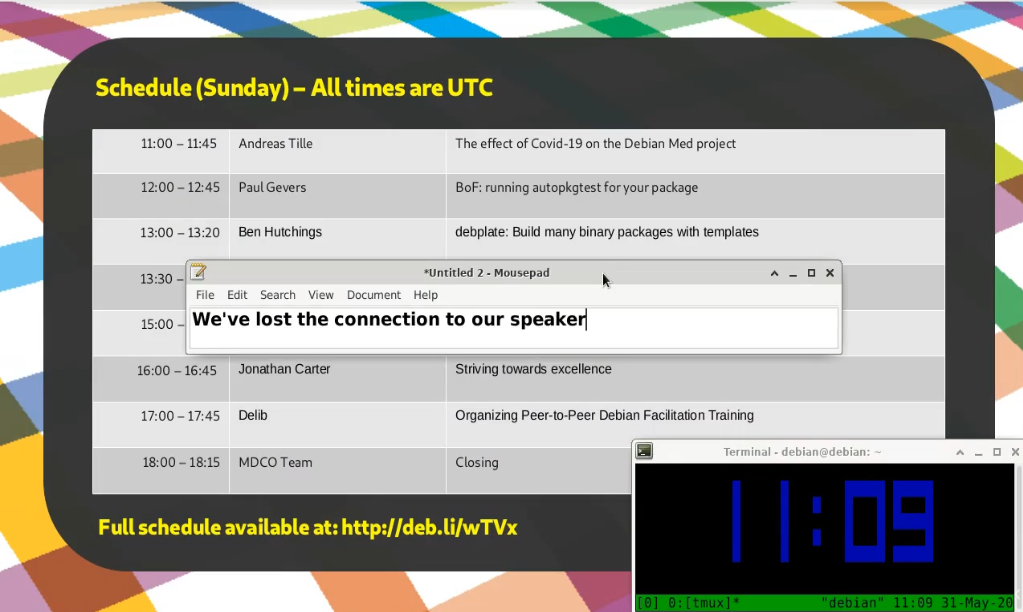
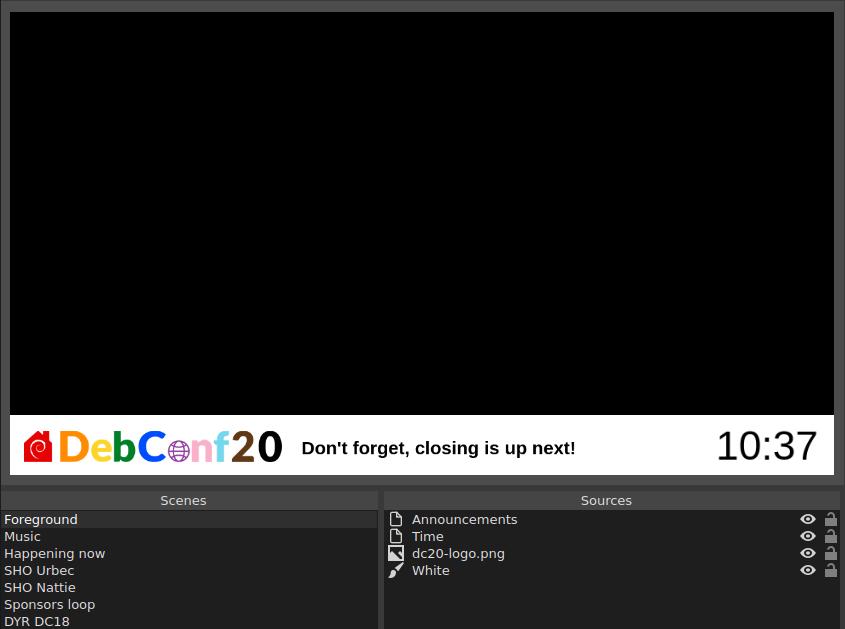
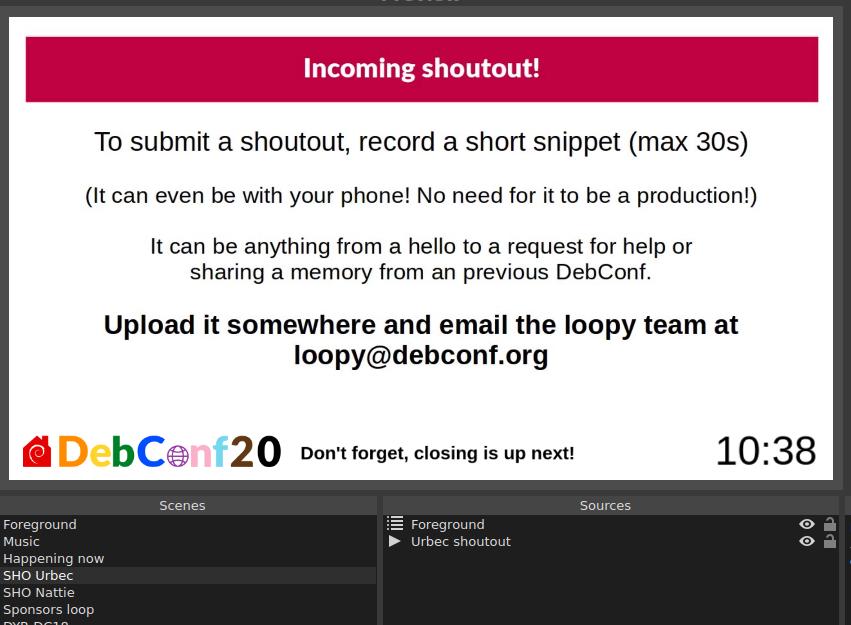
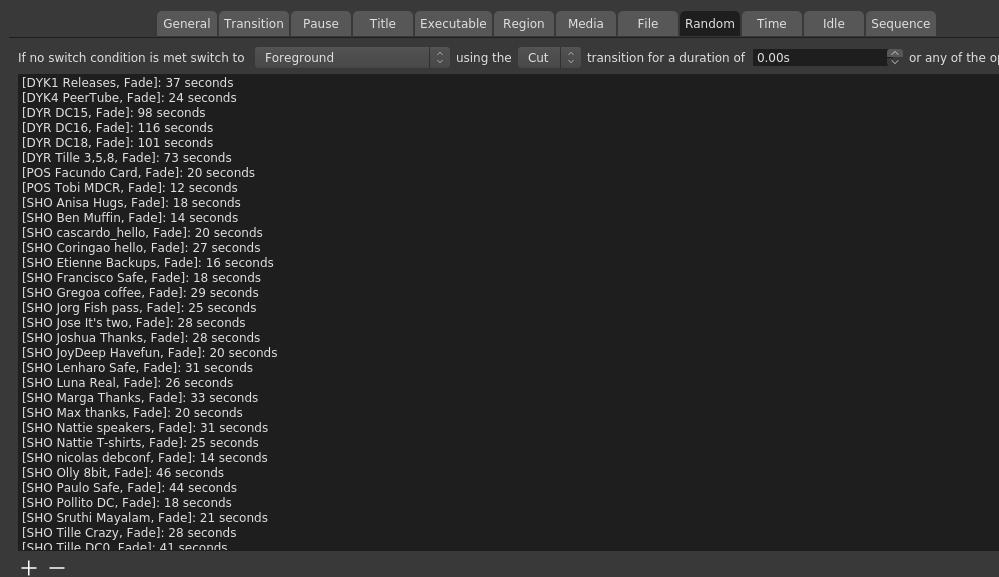
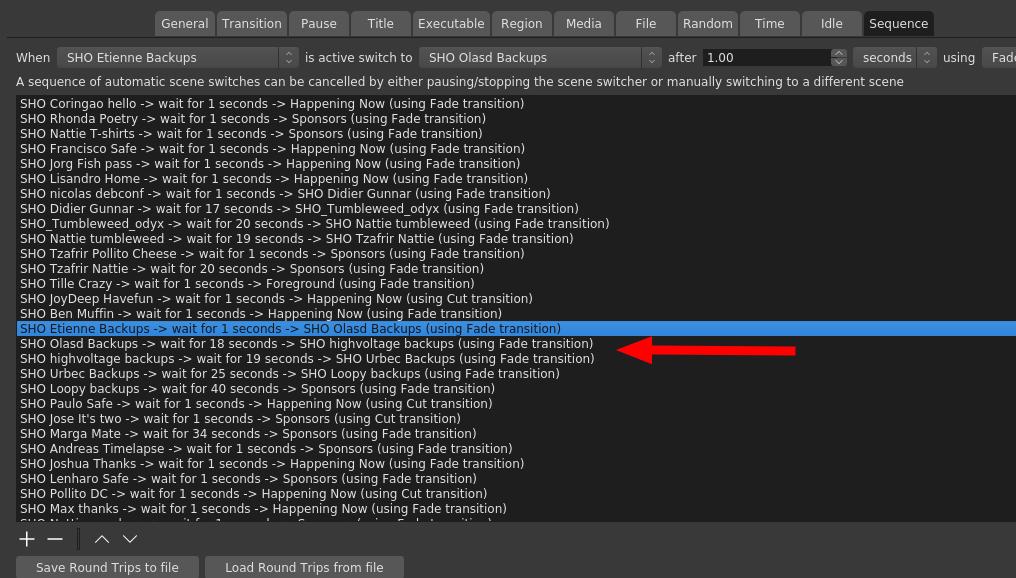
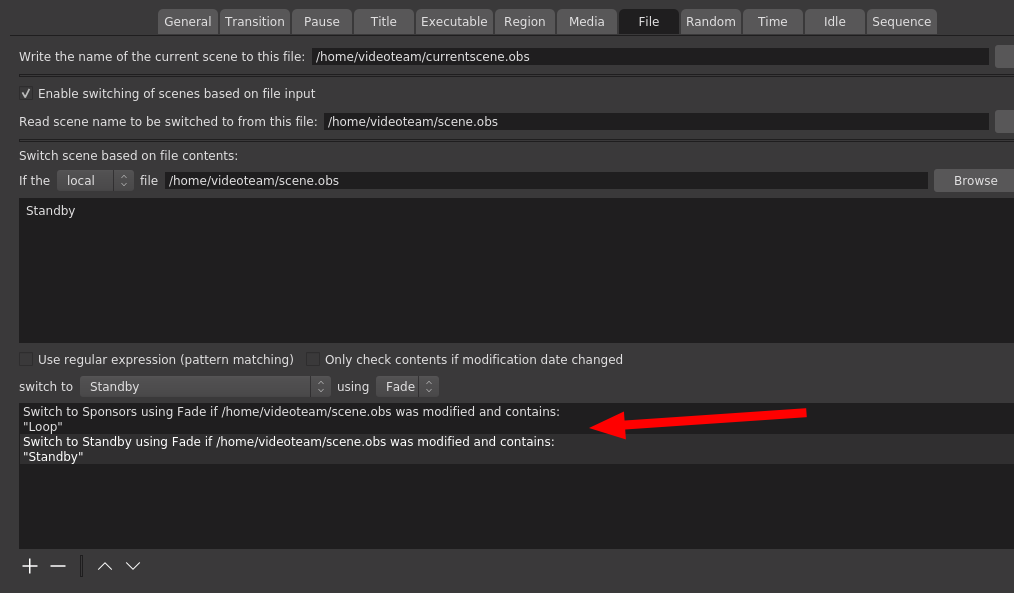
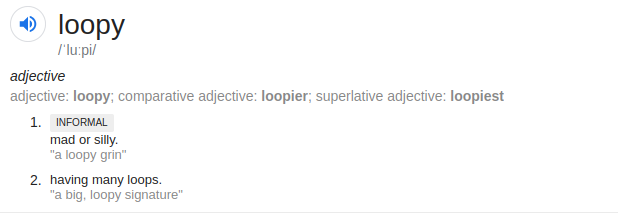




 Something I ve found myself doing as the pandemic rolls on is picking
out and (re-)reading through sections of the
Something I ve found myself doing as the pandemic rolls on is picking
out and (re-)reading through sections of the